PODPAC
Pipeline for Observational Data Processing Analysis and Collaboration
View the Source — Explore Jupyter NotebooksPODPAC is a python library that builds on the scientific python ecosystem to enable simple, reproducible geospatial analyses that run locally or in the cloud.
import podpac
# elevation
elevation = podpac.data.Rasterio(source="elevation.tif")
# soil moisture
soil_moisture = podpac.data.H5PY(source="smap.h5", interpolation="bilinear")
# evaluate soil moisture at the coordinates of the elevation data
output = soil_moisture.eval(elevation.coordinates)
# run evaluation in the cloud
aws_node = podpac.managers.aws.Lambda(source=soil_moisture)
output = aws_node.eval(elevation.coordinates)
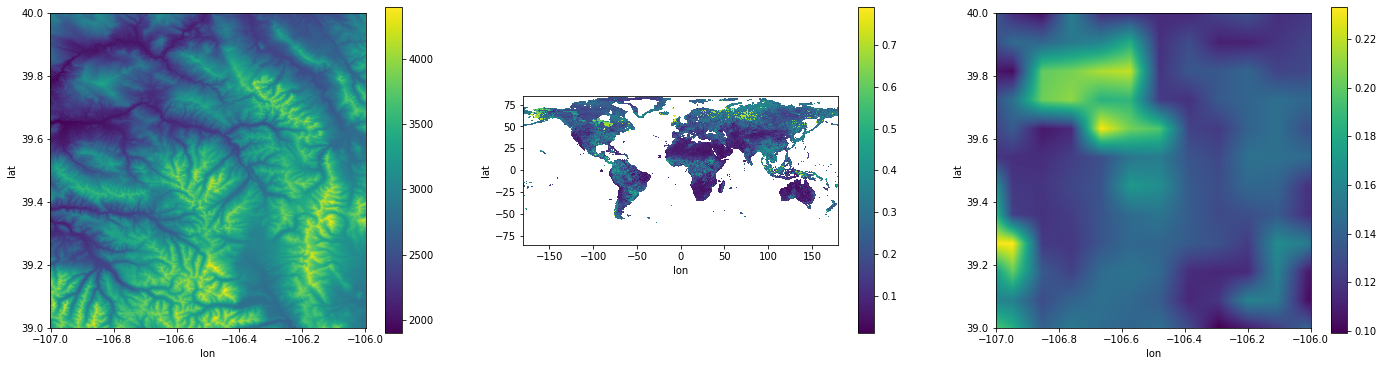
Elevation (left), Soil Moisture (center), Soil Moisture at Elevation coordinates (right).
Purpose
Data wrangling and processing of geospatial data should be seamless so that earth scientists can focus on science. The purpose of PODPAC is to facilitate:
Access of data products
Subsetting of data products
Projecting and interpolating data products
Combining/compositing data products
Analysis of data products
Sharing of algorithms and data products
Use of cloud computing architectures (AWS) for processing
Getting Started
Topics
References
Acknowledgments
This material is based upon work supported by NASA under Contract No 80NSSC18C0061.